第 40 章 流行病学中的逻辑回归
40.1 流行病学研究最常用的实验设计
在流行病学研究中,我们最关心的无非是暴露变量(治疗方案的选用,或者一些对象的某些特征如吸烟或饮酒等生活习惯) 与结果变量(罹患某种我们关心的疾病与否,或者死亡与否) 之间的关系。为了方便解释本章暂且只考虑单一的结果变量(univariate) 的情况,不过不要忘了真实世界中的数据和实验,我们常要**同时处理多个不同的结果变量(multivariate)* *。
流行病学最常用的两种研究设计是:
- 队列研究/前瞻性研究 cohort or prospective studies;
- 病例对照/回顾性研究 case-control or retrospective studies。
无论是这两种研究中的哪一种,都要从定义研究的人群开始 (start by defining some population we wish to study)。例如某个年龄段的男性或者女性;某个特定时间段内,在某特定地区范围内生活的所有人等。这被定义为 潜在研究人群 (underlying population of interest)。
如果是队列研究,我们需要对这个潜在研究人群取样,选取具 有代表性的,且有足够样本量 的一群个体 (队列) 参与研究。那些我们要研究的 暴露变量 \((\mathbf{X})\) 被提前定义好,然后在开始研究的时候收集整理成数据库。之后这个队列的参与者不断被随访,这个时间段可以是先定义好的(一年,五年,十年…),也可以因人而异,最终直至每个个体的结果变量被观测到\((D=1 \text{ or } D=0)\)。更一般地,如果我们要研究的暴露因素是二进制的,甚至是多分类的,我们可能会使用一些取样的技巧,从而保证取样构成的队列能够真实地反应该暴露因子在人群中的分布情况,保证队列的代表性。
如果是病例对照研究,从它的别名– 回顾性研究– 也可以看出,它的研究起点和队列研究相反,是从收集到的病例开始的\((D=1)\) 。有了病例以后,我们从人群中没有该结果变量 \((D=0)\) 的人群中,取适合样本量的人作为对照组。然后再分别对病例和对照组用采访或者问卷,或者调取过去的病例记录/数据库记录等等寻找他们是否接触过我们要研究的暴露变量。
到这里,如果你还没晕,恭喜你应该能理解为什么说病例对照研究研究的是“结果的原因/causes of effect”;队列研究研究的是“原因导致的结果/effect of causes”。二者的终极目标却是一致的 – 寻找暴露和结果二者之间的关系/To investigate the association between exposures and the outcomes – 只是手段不同而已。
观察性研究(不论是队列还是病例对照研究),除了我们一定会测量并收集的暴露变量数据,在分析过程中还不可避免地需要把混杂效应考虑进来,也就是我们还必须测量并收集那些潜在的混杂因子的数据\((W)\)。图40.1 用简单示意图总结了\(W (\text{ confounders }), X (\text{ exposures }), D (\text{ outcomes })\) 之间,在不同实验设计下的关系。
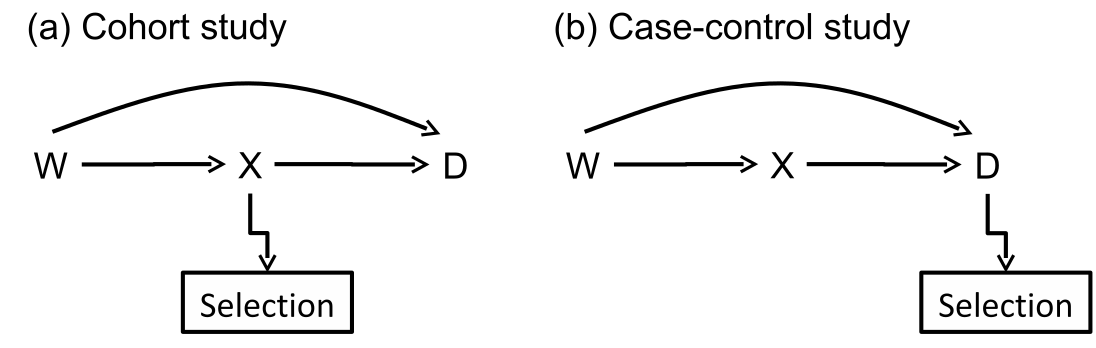
图 40.1: Path diagrams showing relationships between variables in the underlying population and selection to a cohort study and a case-control study.
40.2 以简单二进制暴露变量为例
40.2.1 先决条件
我们以一个最简单的二进制暴露变量 \((X)\) (例如是否接触了某种化学试剂),和一个二进制结果变量 \((D)\) (是否患有食道癌) 为例展开:
- 观察对象样本量为 \(n, i = 1,\cdots,n\);
- \(X_i\) 为一个二进制暴露变量 (是否接触了某种化学试剂,\(1=\)是,\(0=\)否);
- \(D_i\) 为一个二进制结果变量 (是否有食道癌,\(1=\)是,\(0=\)否)。
所以,该研究的潜在研究人群可以被分成四组:\((X=1,D=1),(X=1,D=0),(X=0,D=1),(X=0 ,D=0)\)。如果用 \(\pi_{11}, \pi_{10}, \pi_{01}, \pi_{00}\) 标记每组人在该潜在研究人群中所占的比例,那么有:
\[ \begin{aligned} \pi_{xd} & = \text{Pr}(X=x, D=d) \\ \pi_{11} &+ \pi_{10} + \pi_{01} + \pi_{00} = 1 \end{aligned} \tag{40.1} \]
| \(0\) | \(1\) | ||
|---|---|---|---|
| \(X\) | \(0\) | \(\pi_{00}\) | \(\pi_{01}\) |
| \(1\) | \(\pi_{10}\) | \(\pi_{11}\) |
这里我们应用概率标记法来辅助理解队列研究:我们从潜在研究人群中抽样,观察其暴露情况,再追踪其结果变量。所以实际上,队列研究的样本,来自与对暴露与否 \((X=0, X=1)\) 两组人的抽样,所以我们实际求的是,
\[ \begin{equation} \text{Pr}(D=d|X=x) = \frac{\pi_{xd}}{\pi_{x0} + \pi_{x1}} \end{equation} \]
| \(D\) | \(\text{Pr}(D=d|X=x)\) | ||
|---|---|---|---|
| \(X\) | \(0\) | \(1\) | |
| \(0\) | \(\pi_{00}\) | \(\pi_{01}\) | \(\frac{\pi_{01}}{\pi_{01} + \pi_{00}}\) |
| \(1\) | \(\pi_{10}\) | \(\pi_{11}\) | \(\frac{\pi_{11}}{\pi_{10} + \pi_{11}}\) |
相反地,病例对照研究中我们从已有的病例\((D=1)\) 出发,这样做的理由有很多,通常可能由于病例可能十分稀少,如果建立队列研究可能需要庞大的样本量(即便如此也不一定能够收集到足够分析的数据,可能还要花费相当长的随访时间,吃力不讨好)。所以,在病例对照研究的设计中,我们其实是独立地从两个人群 (病例组,\(D=1\),对照组,\(D=0\)) 中抽取样本。所以,病例对照研究获得的数据,只能用于计算暴露在病例组和对照组中的条件概率:
\[ \text{Pr}(X=x|D=d) = \frac{\pi_{xd}}{\pi_{0d}+\pi_{1d}} \]
| \(0\) | \(1\) | ||
|---|---|---|---|
| \(X\) | \(0\) | \(\pi_{00}\) | \(\pi_{01}\) |
| \(1\) | \(\pi_{10}\) | \(\pi_{11}\) | |
| \(\text{Pr}(X=x|D=d)\) | \(\frac{\pi_{10}}{\pi_{10}+\pi_{00}}\) | \(\frac{\pi_{11}}{\pi_{11}+\pi_{01}}\) |
40.2.2 比值比 Odds ratios
某研究的数据中,暴露变量是二进制的 \(X\),和 结果变量是二进制的 \(D\)。我们其实最关心的问题是:结果变量的两个分类 \(D=0, D=1\),在暴露变量 \(X=0, X=1\) 两组中到底个占多少比例。用吸烟与肺癌的例子来解释就是,我们最关心的是,在吸烟人群中,发生肺癌的人的比例,是否显著地高于非吸烟人群中发生肺癌的人的比例,仅此而已。这句话用概率论的标记法来写的话,则是两个条件概率:$(D=1|X=1), (D=1|X=0) $。此处,可以定义暴露变量 \(X=1\) 的条件下,结果变量 \(D=1\) 的概率的比值 (Odds):
\[ \text{Odds}_1 = \frac{\text{Pr}(D=1|X=1)}{1-\text{Pr}(D=1|X=1)} = \frac{\pi_{ 11}/(\pi_{10} + \pi_{11})}{1-\pi_{11}/(\pi_{10} + \pi_{11})} \]
类似地,暴露变量 \(X=0\) 的条件下,结果变量 \(D=1\) 的概率的比值 (Odds):
\[ \text{Odds}_2 = \frac{\text{Pr}(D=1|X=0)}{1-\text{Pr}(D=1|X=0)} = \frac{\pi_{ 01}/(\pi_{01} + \pi_{00})}{1-\pi_{01}/(\pi_{01} + \pi_{00})} \]
故,从队列研究中,可以很自然的计算暴露变量和结果变量的比值比:
\[ \begin{aligned} \text{Odds Ratio}_{\text{cohort}} = \frac{\text{Odds}_1}{\text{Odds}_2} & = \frac{\frac{\text{Pr}(D=1 |X=1)}{1-\text{Pr}(D=1|X=1)}}{\frac{\text{Pr}(D=1|X=0)}{1-\text{ Pr}(D=1|X=0)}}\\ & = \frac{\frac{\pi_{11}/(\pi_{10} + \pi_{11})}{1-\pi_{11}/(\pi_{10} + \pi_{11}) }}{\frac{\pi_{01}/(\pi_{01} + \pi_{00})}{1-\pi_{01}/(\pi_{01} + \pi_{00})}} \\ & = \frac{\frac{\pi_{11}/(\pi_{10}+\pi_{11})}{\pi_{10}/(\pi_{10}+\pi_{11})}} {\frac{\pi_{01}/(\pi_{01}+\pi_{00})}{\pi_{00}/(\pi_{01}+\pi_{00})}} \\ & = \frac{\pi_{11}\pi_{00}}{\pi_{10}\pi_{01}} \end{aligned} \]
从病例对照研究中,推算的暴露变量和结果变量的比值比是另外一个过程:
\[ \begin{aligned} \text{Odds Ratio}_{\text{case-control}} = \frac{\text{Odds}^\prime_1}{\text{Odds}^\prime_2} & = \frac{\frac{\text{ Pr}(X=1|D=1)}{1-\text{Pr}(X=1|D=1)}}{\frac{\text{Pr}(X=0|D=0)} {1-\text{Pr}(X=0|D=0)}} \\ & = \frac{\frac{\pi_{11}/(\pi_{11} + \pi_{01})}{1-\pi_{11}/(\pi_{11} + \pi_{01}) }}{\frac{\pi_{10}/(\pi_{10} + \pi_{00})}{1-\pi_{10}/(\pi_{10} + \pi_{00})}} \\ & = \frac{\frac{\pi_{11}/(\pi_{11}+\pi_{01})}{\pi_{01}/(\pi_{11}+\pi_{01})}} {\frac{\pi_{10}/(\pi_{10}+\pi_{00})}{\pi_{00}/(\pi_{10}+\pi_{00})}} \\ & = \frac{\pi_{11}\pi_{00}}{\pi_{10}\pi_{01}} \end{aligned} \]
经过上面的推演,我们发现用病例对照研究的数据,虽然不能像队列研究一样直接推算正确的暴露条件下的比值(conditional odds given exposure),却能用较少的样本量中获得真实的比值比(OR) 。
40.2.3 逻辑回归应用于病例对照研究的合理性
在一个队列研究中,当我们有不止一个暴露变量时,显然就需要更加复杂的模型来辅助分析 (回归型分析法) 暴露变量和结果变量之间的关系。估计比值比最佳的模型是逻辑回归。如果 \(D\) 表示一个随机型结果变量,其中每个观察对象的结果变量服从暴露变量的条件二项分布 (继续用单一的二进制暴露变量 \(x_i\)):
\[ D_i|X_i = x_i \sim \text{Binomial}(1, \pi_i) \]
所以,可以用逻辑回归来拟合:
\[ \text{logit}(\pi_i) = \text{log}(\frac{\pi_i}{1-\pi_i}) = \alpha + \beta x_i \]
把这个逻辑回归方程重新整理:
\[ \begin{aligned} \text{Pr}(D=1|X=1) & = \frac{e^{\alpha + \beta}}{1 + e^{\alpha + \beta}} \\ \text{Pr}(D=1|X=0) & = \frac{e^\alpha}{1 + e^\alpha} \\ \text{Where, }\alpha & = \text{log}{\frac{\pi_{01}}{\pi_{00}}} \\ \beta & = \text{log}{\frac{\pi_{11}\pi_{00}}{\pi_{10}\pi_{01}}} \end{aligned} \]
在一个病例对照研究中,结果变量 \(D_i\) 被锁死,暴露变量成了服从结果变量的条件二项分布的随机变量:
\[ X_i | D_i = d_i \sim \text{Binomial}(1,\pi_i^*) \]
继续任性地用逻辑回归拟合的话:
\[ \text{logit}(\pi_i^*) = \text{log}(\frac{\pi_i^*}{1-\pi_i^*}) = \alpha^* + \beta d_i \]
同样整理成概率方程:
\[ \begin{aligned} \text{Pr}(X=1|D=1) & = \frac{e^{\alpha^* + \beta}}{1 + e^{\alpha^* + \beta}} \\ \text{Pr}(X=1|D=0) & = \frac{e^{\alpha^*}}{1 + e^{\alpha^*}} \\ \text{Where, }\alpha & = \text{log}{\frac{\pi_{10}}{\pi_{00}}} \\ \beta & = \text{log}{\frac{\pi_{11}\pi_{00}}{\pi_{10}\pi_{01}}} \end{aligned} \]
所以,用逻辑回归拟合病例对照研究的数据,同样可以得到和队列研究一样正确的比值比估计。但是这个截距\(\alpha\),在队列研究中指的是,非暴露组中患病的比值的对数(log odds of disease in the unexposed);在病例对照研究中指的是,对照组中暴露的比值的对数(log odds of exposure in the controls)。是两个完全不同含义的估计量。
综上所述,从一个队列研究获得的似然方程是:
\[ \begin{aligned} L_{\text{cohort}} & = \prod_{i=1}^n(\frac{e^{\alpha + \beta x_i}}{1+e^{\alpha + \beta x_i}})^ {d_i}(\frac{1}{e^{\alpha + \beta x_i}})^{1-d_i} \\ \text{Where } d_i & = \left\{ \begin{array}{ll} 0 \text{ if subjects were not observed with the outcome}\\ 1 \text{ if subjects were observed with the outcome}\\ \ end{array} \right. \\ x_i & = \left\{ \begin{array}{ll} 0 \text{ if subjects were not observed with the exposure}\\ 1 \text{ if subjects were observed with the exposure}\\ \end{array} \ right. \end{aligned} \]
从一个病例对照研究获得的似然方程是:
\[ \begin{aligned} L_{\text{case-control}} & = \prod_{i=1}^n(\frac{e^{\alpha + \beta d_i}}{1+e^{\alpha + \beta d_i}} )^{x_i}(\frac{1}{e^{\alpha + \beta d_i}})^{1-x_i} \\ \text{Where } d_i & = \left\{ \begin{array}{ll} 0 \text{ if subjects were not observed with the outcome}\\ 1 \text{ if subjects were observed with the outcome}\\ \ end{array} \right. \\ x_i & = \left\{ \begin{array}{ll} 0 \text{ if subjects were not observed with the exposure}\\ 1 \text{ if subjects were observed with the exposure}\\ \end{array} \ right. \end{aligned} \]
40.3 拓展到多个暴露变量的逻辑回归模型
现在来考虑 \(p\) 个暴露变量的情况:\(X_1, \cdots, X_p\),这些暴露变量可以是分类型变量,也可以是连续型变量,例如,
- \(D_i = 0 \text{ or } 1\),第 \(i\) 名研究对象观察到有 \((=1)\),或没有 \((=0)\) 结果变量 (如发生胰腺癌);
- \(X_{i1} = 0 \text{ or } 1\),第 \(i\) 名研究对象有 \((=1)\),或没有 \((=0)\) 暴露变量 (如吸烟);
- \(X_{i2} = 0 \text{ or } 1\),第 \(i\) 名研究对象是男性 \((=1)\),或女性 \((=0)\);
- \(X_{i3}\),第 \(i\) 名研究对象的年龄 (years)。
40.3.1 Mantel Haenszel 法
如果数据有且只有两个暴露变量,\(X_1, X_2\),其中 \(X_1\) 是一个二进制变量,\(X_2\) 是一个可以分成 \(C\) 组的分类变量。那么如果样本量足够大,可以把数据整理成 \(C\) 个四格表用于分析每一个 \(X_2\) 的分层中 \(X_1\) 和结果变量 \(D\) 之间的关系。多层数据的合并比值比可以用 Mantel Haenszel 法。此法在两个分类暴露变量的情况下还能适用,当某个(或两个)分类变量的层数越来越多时,你会发现最终落到小格子里的样本量急剧下降,局限性就体现了出来。另外,此法亦不能应用于连续型变量的调整,用处简直就是捉襟见肘。迫切地我们需要有更加一般的 (借助于回归的威力的) 方法来对多个暴露变量进行调整。
40.3.2 队列研究和病例对照研究的似然
一个队列研究,用逻辑回归拟合其结果变量 (因变量) \(D\) 和暴露变量 \(X_1, \cdots, X_p\) 之间的关系时,可以写作:
\[ \begin{aligned} D_i=1 | (X_{i1} & = x_{i1}, \cdots, X_{ip} = x_{ip}) \sim \text{Binomial}(1, \pi_i) \\ \text{logit} (\pi_i) & = \text{log}(\frac{\pi_i}{1-\pi_i}) = \alpha + \beta_1 x_{i1} + \cdots + \beta_p x_{ip} \end{aligned} \]
将这个回归方程重新整理成为概率方程:
\[ \text{Pr}(D_i = 1 | X_{i1} = x_{i1}, \cdots, X_{ip} = x_{ip}) = \frac{e^{\alpha + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}}{1+e^{\alpha + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}} \]
- 截距 \(\alpha\) 的含义是,当所有的暴露变量都取 \(0\) 时,研究对象观察到结果变量为 \(1\) 的对数比值 \((\text{log odds})\);
- 回归系数\(\beta_k\) 的含义是,当其余的暴露变量保持不变时,\(x_k\) 每增加一个单位,结果变量为\(1\) 的对数比值比\((\text{log odds-ratio})\) (即,调整了其余所有变量之后,\(x_k\) 和结果变量之间的对数比值比)。
所以,队列研究的数据,其似然方程是:
\[ \begin{aligned} L_{\text{cohort}} & = \prod_{i=1}^n\text{Pr}(D_i = d_i | X_{i1} = x_{i1}, \cdots, X_{ip} = x_{ip }) \\ & = \prod_{i=1}^n\text{Pr}(\frac{e^{\alpha + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}}{1+e^{ \alpha + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}})^{d_i}(\frac{1}{1+e^{\alpha + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}})^{1-d_i} \end{aligned} \]
当数据变成了病例对照研究,其似然方程会变成怎样呢?
\[ L_{\text{case-control}} = \prod_{i=1}^n\text{Pr}(X_{i1} = x_{i1}, \cdots, X_{ip} = x_{ip} |D_i = d_i) \]
这里,我们很难看出这到底是怎样的一个条件概率,如果预测变量中同时包括了连续型变量和分类变量,情况就更加复杂,剪不断理还乱。
40.3.3 病例对照研究中的逻辑回归
用 \(\text{Pr}(S_i=1 \text{ or } 0)\) 表示在潜在研究人群 (underlying study population) 中,被抽样 (或者没有被抽样) 进入该队列研究的概率。那么,理想情况下,可认为实施病例对照研究时,病例是稀少的,即我们收集到的病例,几乎等价于我们关心的潜在研究人群中全部的病例,且可以被证明:
\[ \begin{aligned} & \text{Pr}(X_{i1} = x_{i1}, \cdots, X_{ip} = x_{ip} |D_i = 1) \\ =& \text{Pr}(X_{i1} = x_{i1}, \cdots, X_{ip} = x_{ip} |D_i = 1, S_i=1) \\ =& \frac{e^{\alpha^* + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}}{1+e^{\alpha^* + \beta_1 x_{i1} + \ cdots + \beta_p x_{ip}}} \\ & \;\;\;\; \times \frac{\text{Pr}(X_{i1} = x_{i1}, \cdots, X_{ip} = x_{ip} |S_i=1)}{\text{Pr}(D_i = 1 | S_i = 1)} \\ \text{Where } \alpha^* & = \alpha + \text{log}(\frac{\text{Pr}(D_i = 0)}{\text{Pr}(D_i = 1)}) + \text {log}(\frac{\text{Pr}(D_i = 1|S_i=1)}{\text{Pr}(D_i = 0|S_i=1)}) \end{aligned} \tag{40.2} \]
概率方程(40.2) 中,可以看出第一部分\(\frac{e^{\alpha^* + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}}{ 1+e^{\alpha^* + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}}\) 是一个逻辑回归模型。跟队列研究的逻辑回归模型相比较,差别只是截距不同 \(\alpha \neq \alpha^*\)。其余的部分如\(\text{Pr}(X_{i1} = x_{i1}, \cdots, X_{ip} = x_{ip} |S_i=1)\) 的含义是潜在人群中被取样放入该队列研究,且预测变量各自不同的随机概率分布,其实和我们寻找的参数\(\beta_1,\cdots,\beta_p\),是没有什么关系的。最后一部分分母的\(\text{Pr}(D_i = 1 | S_i = 1)\) 的意思是,结果变量为\(1\) 的人被选入本项病例对照研究的概率,理想的实验设计下这被认为是接近于\(1\) 的,即使不是,它也是一个固定不变的常数。所以,病例对照研究的似然方程中,我们关心的只有第一部分,逻辑回归模型:
\[ L_{\text{case-control}} \propto \prod_{i=1}^n(\frac{e^{\alpha^* + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}} }{1+e^{\alpha^* + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}})^{d_i}(\frac{1}{1+e^{\alpha^ * + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}}})^{1-d_i} \]
这里必须明确的一点是,病例对照研究拟合的逻辑回归,其截距是 \(\alpha^*\),并非 \(\alpha\)。这个 \(\alpha^*\) 其实是包含了 \(\text{Pr}(D_i=1),\text{Pr}(D_i=0)\) 的,可惜这些概率也无法用病例对照研究设计获得。所以,病例对照研究数据拟合了逻辑回归模型以后的截距,其实没有太多实际的含义。
40.4 流行病学研究中变量的调整策略
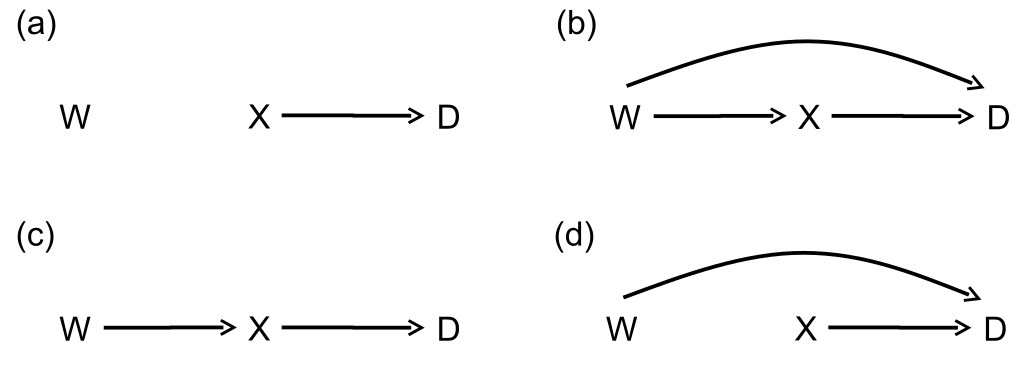
图 40.2: relationships between three variables in an underlying population of interest
图40.2 展示的是在潜在研究人群中\(W (\text{potential confounder}),X (\text{exposure}),D (\text{outcome})\) 三者之间可能存在的四种关系。
- 图40.2 - (a) \(W\) 和\(X, D\) 都没有关系,那么我们研究\(X,D\) 之间的关系时,完全可以忽略掉\(W\) ,不用调整。
但是,如果在逻辑回归模型中调整了一个和暴露变量结果变量之间无关的变量,获得的比值比估计几乎不会有太大改变,但是代价是会获得较大的对数比值比的标准误(standard error),降低了对比值比估计的精确程度。 - 图40.2 - (b) \(W\) 和\(X, D\) 同时都相关,且不在\(X\rightarrow D\) 的因果关系通路上,此种情况下,必须对\(W\) 进行调整,否则获得的比值比估计是带有严重偏倚的。
- 图 40.2 - (c) \(W\) 仅仅和 \(X\) 有关系,和结果变量 \(D\) 没有相关性。此时研究 \(X,D\) 之间的关系时,忽略掉 \(W\),不需要对之进行任何调整。和 (a) 一样,如果此时调整了 \(W\),估计的比值比不会发生质变,但是会损失估计的精确度。
- 图40.2 - (d) \(W\) 仅仅和结果变量\(D\) 有关系,和暴露变量\(X\) 无关时,如果模型对\(W\) 进行调整,我们会获得完全不同的比值比估计,因为这种情况下其实调整\(W\) 前后的比值比估计的是具有不同含义的,二者都具有实际意义。调整前的估计量,是总体估计,有助于作总体的决策;调整后的估计量,是带有某些特征的部分人群估计,有助于评价个人水平的\(X,D\) 之间的关系。
40.5 GLM例8
40.5.1 Part 1
在第一部分的数据分析中,我们会使用逻辑回归模型来分析来自病例对照研究设计的数据,并获取比值比 (odds ratios)。
该病例对照研究数据来自一项关于食道癌的研究 (Breslow, Day, and research 1980)。病例是200名被诊断为患有食道癌的法国男性。对照组则来自176名健康男性。
数据包含的变量及其解释描述如下:
| Variable Name | Content |
|---|---|
case |
1 = case, 0 = control |
age_group |
age group [1: 25-34; 2: 35-44; 3: 45-54; 4: 55-64; 5: 65-74; 6: 75+] |
tobacco_group |
tobacco intake group [0: None; 1: 1-9 g/d; 2: 10-19 g/d; 3: 20-29 g/day; 4: 30+ g/d] |
alcohol_grp |
alcohol intake group [0: 0-39 g/d; 1: 40-79 g/d; 80-119 g/d; 3: 120+ g/d] |
该研究的主要目的是分析吸烟量 tobacco_group 与饮酒量 alcohol_grp 是否是食道癌的危险因子。变量中的年龄 age_group 则作为唯一已知的混杂因子。
40.5.1.1 简单初步总结各个解释变量的分布及特征。思考吸烟量和饮酒量,吸烟量和年龄之间有怎样的关系。
library(haven)
library(Epi)
Oesophageal <- read_dta("../Datas/oesophageal_data-3.dta")
tab <- stat.table(index=list(Tobacco_gr = tobacco_group,
Alcohol_gr = alcohol_grp),
contents=list(count(),
percent(alcohol_grp)),
data=Oesophageal, margins=TRUE)
print(tab, digits = 2) -----------------------------------------------------
---------------Alcohol_gr----------------
Tobacco_gr 0 1 2 3 Total
-----------------------------------------------------
0 148.00 83.00 27.00 6.00 264.00
56.06 31.44 10.23 2.27 100.00
1 112.00 97.00 35.00 18.00 262.00
42.75 37.02 13.36 6.87 100.00
2 84.00 85.00 49.00 18.00 236.00
35.59 36.02 20.76 7.63 100.00
3 42.00 62.00 16.00 12.00 132.00
31.82 46.97 12.12 9.09 100.00
4 28.00 29.00 12.00 13.00 82.00
34.15 35.37 14.63 15.85 100.00
Total 414.00 356.00 139.00 67.00 976.00
42.42 36.48 14.24 6.86 100.00
----------------------------------------------------- tab <- stat.table(index=list(Tobacco_gr = tobacco_group,
Age_gr = age_group),
contents=list(count(),
percent(age_group)),
data=Oesophageal, margins=TRUE)
print(tab, digits = 2) ---------------------------------------------------------------------
-------------------------Age_gr--------------------------
Tobacco_gr 1 2 3 4 5 6 Total
---------------------------------------------------------------------
0 50.00 69.00 56.00 50.00 26.00 13.00 264.00
18.94 26.14 21.21 18.94 9.85 4.92 100.00
1 21.00 40.00 48.00 67.00 73.00 13.00 262.00
8.02 15.27 18.32 25.57 27.86 4.96 100.00
2 19.00 46.00 57.00 65.00 38.00 11.00 236.00
8.05 19.49 24.15 27.54 16.10 4.66 100.00
3 11.00 27.00 33.00 38.00 20.00 3.00 132.00
8.33 20.45 25.00 28.79 15.15 2.27 100.00
4 16.00 17.00 19.00 22.00 4.00 4.00 82.00
19.51 20.73 23.17 26.83 4.88 4.88 100.00
Total 117.00 199.00 213.00 242.00 161.00 44.00 976.00
11.99 20.39 21.82 24.80 16.50 4.51 100.00
--------------------------------------------------------------------- 似乎在吸烟量和饮酒量之间存在正关系,吸烟较多的人,饮酒量也呈现较多的趋势。另外,不吸烟的人中,以及吸烟量最多的人中,都有较多的年轻人。吸烟量和饮酒量也许都和患有食道癌相关。而且上述简单的表格总结也提示,吸烟量同时和饮酒量和年龄相关。
40.5.1.2 我们先从分析吸烟习惯着手。将研究对象根据吸烟习惯分为吸烟者 (tobacco_group = 1~4) 与非吸烟者 (tobacco_group = 0)。使用2 \(\times\) 2表格分析吸烟与否和患有食道癌与否之间的关系。使用公式手头计算比值比 0dds ratio,和它的 95% 置信区间。用统计软件确认你的计算结果是否正确。
library(tidyverse)
Oesophageal <- Oesophageal %>%
mutate(Tobacco_2 = as.factor(tobacco_group)) %>%
mutate(Tobacco_2 = fct_collapse(Tobacco_2,
NonSMker = "0",
SMker = c("1", "2", "3", "4")))
tab <- stat.table(index=list(Case = case,
Tobacco_gr = Tobacco_2),
contents=list(count(),
percent(Tobacco_2)),
data=Oesophageal, margins=TRUE)
print(tab, digits = 2) ---------------------------------
--------Tobacco_gr--------
Case NonSMker SMker Total
---------------------------------
0 255.00 521.00 776.00
32.86 67.14 100.00
1 9.00 191.00 200.00
4.50 95.50 100.00
Total 264.00 712.00 976.00
27.05 72.95 100.00
--------------------------------- 手动计算比值比和95%置信区间:
[1] 0.1221877[1] 10.38708 5.23537 20.60816所以,从表格推算的比值比 OR = 10.39;该比值比的对数对应的分布方差估算为 0.122。据此,该比值比的 95% CI为 (5.24, 20.61)。有很强的证据表明,吸烟习惯的有无和患有食道癌之间有正关系。
用R验证你的计算结果:
case
Tobacco_2 0 1 Total
NonSMker 255 9 264
SMker 521 191 712
Total 776 200 976
OR = 10.39
95% CI = 5.24, 20.61
Chi-squared = 64.82, 1 d.f., P value = 0
Fisher's exact test (2-sided) P value = 0 用 Stata 做一样的事情:
(976 missing values generated)
(264 real changes made)
(712 real changes made)
Maximum likelihood estimate of the odds ratio
Comparing tobacco_2==1 vs. tobacco_2==0
----------------------------------------------------------------
Odds Ratio chi2(1) P>chi2 [95% Conf. Interval]
----------------------------------------------------------------
10.387076 64.75 0.0000 5.109681 21.115085
----------------------------------------------------------------值得注意的是,Stata 里面的 mhodds 用的是不同于R的方法计算 95% 置信区间的。
40.5.1.3 考虑使用逻辑回归模型来获取我们感兴趣的比值比。请用数学语言写下下列两个模型的表达式:
- 吸烟与否为结果变量,病例和对照的标记为预测变量。
令 \(X\) 为吸烟与否变量,\(D\) 为病例/对照标记变量。
\[ \text{Pr}(X = 1 | D = d) = \frac{e^{\alpha^* + \beta d}}{1 + e^{\alpha^* + \beta d}} \]
- 病例和对照的标记为结果变量,吸烟与否为预测变量。
使用相同的标记来表达这个模型,另外,用 \(S = 1\) 表示该对象被选做本次研究的病例-对照样本。所以,在下面的模型中,不要忘记我们还有一个条件变量,也就是该对象被选入本次实验中。
\[ \text{Pr}(D = 1|X = x, S = 1) = \frac{e^{\lambda^* + \beta x}}{1 + e^{\lambda^* + \beta x} } \]
40.5.1.4 用你熟悉的统计软件分别拟合上述两个逻辑回归模型。比较两个解析报告的结果,并试着解释他们各自的截距估计量的含义。用概率的数学表达式来说明二者的不同。
M1 <- glm(Tobacco_2 ~ case,
data = Oesophageal,
family = binomial(link = logit))
summary(M1); jtools::summ(M1, digits = 6, confint = TRUE, exp = TRUE)
Call:
glm(formula = Tobacco_2 ~ case, family = binomial(link = logit),
data = Oesophageal)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.71449 0.07643 9.349 < 2e-16 ***
case 2.34056 0.34951 6.697 2.13e-11 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1139.5 on 975 degrees of freedom
Residual deviance: 1056.1 on 974 degrees of freedom
AIC: 1060.1
Number of Fisher Scoring iterations: 5| Observations | 976 |
| Dependent variable | Tobacco_2 |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(1) | 83.357682 |
| Pseudo-R² (Cragg-Uhler) | 0.118838 |
| Pseudo-R² (McFadden) | 0.073154 |
| AIC | 1060.117214 |
| BIC | 1069.884140 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 2.043137 | 1.758910 | 2.373294 | 9.348719 | 0.000000 |
| case | 10.387076 | 5.235833 | 20.606336 | 6.696606 | 0.000000 |
| Standard errors: MLE |
M2 <- glm(case ~ Tobacco_2,
data = Oesophageal,
family = binomial(link = logit))
summary(M2); jtools::summ(M2, digits = 6, confint = TRUE, exp = TRUE)
Call:
glm(formula = case ~ Tobacco_2, family = binomial(link = logit),
data = Oesophageal)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.3440 0.3392 -9.860 < 2e-16 ***
Tobacco_2SMker 2.3406 0.3496 6.696 2.14e-11 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 989.95 on 975 degrees of freedom
Residual deviance: 906.59 on 974 degrees of freedom
AIC: 910.59
Number of Fisher Scoring iterations: 6| Observations | 976 |
| Dependent variable | case |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(1) | 83.357682 |
| Pseudo-R² (Cragg-Uhler) | 0.128443 |
| Pseudo-R² (McFadden) | 0.084204 |
| AIC | 910.589629 |
| BIC | 920.356554 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 0.035294 | 0.018155 | 0.068612 | -9.859637 | 0.000000 |
| Tobacco_2SMker | 10.387076 | 5.235437 | 20.607897 | 6.695866 | 0.000000 |
| Standard errors: MLE |
你看到两个模型计算出的比值比结果是完全一致的。这符合我们的预期。
其中,第一个模型的截距 \(\exp(\hat{\alpha*}) = 2.043\)。用概率的数学表达式表达为: \(\exp(\hat{\alpha*}) =\text{Pr}(X=1 | D=0)/\text{Pr}(X = 0 | D = 0 )\)。我们可以从原始的表格中的数据直接计算来获得验证:
\[ \text{Pr}(X=1|D=0) = 521/776 = 0.6714 \\ \text{Pr}(X=0|D=0) = 255/776 = 0.3286 \\ \Rightarrow \frac{\text{Pr}(X=1|D=0)}{\text{Pr}(X=0|D=0)} = \frac{0.6714}{0.3286} = 2.043 \]
在另外一个模型中的截距 \(\exp(\hat{\lambda}) = 0.035\)。从该模型的数学表达式出发,不难知道:
\[ \begin{aligned} \exp(\lambda^*) & = \frac{\text{Pr}(D = 1 | X = 0, S = 1)}{\text{Pr}(D = 0 | X = 0, S = 1 )} \\ & = \frac{9 / 264}{255 / 264} = 0.03529 \end{aligned} \]
40.5.1.5 接下来我们将要分析酒精摄入量对上述关系可能存在的影响。请尝试使用 Mantel-Haenszel 法来计算酒精摄入量调整后的吸烟与食道癌的比值比。调整了饮酒量之后的比值比发生了多大的变化?
(976 missing values generated)
(264 real changes made)
(712 real changes made)
Maximum likelihood estimate of the odds ratio
Comparing tobacco_2==1 vs. tobacco_2==0
by alcohol_grp
-------------------------------------------------------------------------------
alcoho~p | Odds Ratio chi2(1) P>chi2 [95% Conf. Interval]
----------+--------------------------------------------------------------------
0-39 gra | . 17.31 0.0000 . .
40-79 gr | 9.552239 19.77 0.0000 2.82084 32.34690
80-119 g | 3.066667 4.73 0.0296 1.05865 8.88347
120+ gra | 12.941176 7.51 0.0061 1.20415 139.08120
-------------------------------------------------------------------------------
Mantel-Haenszel estimate controlling for alcohol_grp
----------------------------------------------------------------
Odds Ratio chi2(1) P>chi2 [95% Conf. Interval]
----------------------------------------------------------------
8.587244 46.47 0.0000 4.079007 18.078115
----------------------------------------------------------------
Test of homogeneity of ORs (approx): chi2(3) = 6.09
Pr>chi2 = 0.1073调整酒精摄入量之后,可见吸烟与食道癌的比值比 OR 从 10.39 略微降低到 8.59。与第一步的问题相结合,当时我们发现吸烟与饮酒之间有关联,所以综合以上信息可以认为饮酒量是吸烟与食道癌关系的混杂因子 (confounder)。但是吸烟者与食道癌之间的强正关系 (strong positive association) 在调整了饮酒量之后依然是有统计学意义的。调整了饮酒量之后,吸烟者患有食道癌的比值 (odds) 高过不吸烟的人8倍以上。
40.5.1.6 请拟合合适的模型重复上述的分析,根据模型报告的结果寻找能够评价调整了饮酒量以后的吸烟与患有食道癌之间关系的比值比及其置信区间。解释该模型的截距的含义是什么。
M3 <- glm(case ~ Tobacco_2 + as.factor(alcohol_grp),
data = Oesophageal,
family = binomial(link = logit))
summary(M3); jtools::summ(M3, digits = 6, confint = TRUE, exp = TRUE)
Call:
glm(formula = case ~ Tobacco_2 + as.factor(alcohol_grp), family = binomial(link = logit),
data = Oesophageal)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -4.3059 0.3854 -11.173 < 2e-16 ***
Tobacco_2SMker 2.1265 0.3588 5.926 3.10e-09 ***
as.factor(alcohol_grp)1 1.1456 0.2366 4.841 1.29e-06 ***
as.factor(alcohol_grp)2 1.9182 0.2682 7.154 8.46e-13 ***
as.factor(alcohol_grp)3 3.0994 0.3350 9.251 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 989.95 on 975 degrees of freedom
Residual deviance: 786.56 on 971 degrees of freedom
AIC: 796.56
Number of Fisher Scoring iterations: 6| Observations | 976 |
| Dependent variable | case |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(4) | 203.383008 |
| Pseudo-R² (Cragg-Uhler) | 0.295141 |
| Pseudo-R² (McFadden) | 0.205448 |
| AIC | 796.564303 |
| BIC | 820.981616 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 0.013489 | 0.006338 | 0.028708 | -11.173058 | 0.000000 |
| Tobacco_2SMker | 8.385601 | 4.150364 | 16.942686 | 5.926028 | 0.000000 |
| as.factor(alcohol_grp)1 | 3.144379 | 1.977466 | 4.999894 | 4.841238 | 0.000001 |
| as.factor(alcohol_grp)2 | 6.808843 | 4.025526 | 11.516593 | 7.153511 | 0.000000 |
| as.factor(alcohol_grp)3 | 22.185079 | 11.504870 | 42.779944 | 9.251133 | 0.000000 |
| Standard errors: MLE |
结论其实是一样的。调整了饮酒量之后,吸烟者患有食道癌的比值高于非吸烟者 8 倍以上。另外,饮酒量的增加也与食道癌呈正相关。调整了吸烟量之后,饮酒量最多的人患有食道癌的比值比饮酒量最少的人高22倍以上。这个模型里的截距可以用下列的数学表达式来解释:
\[ \exp(\hat{\lambda^*}) = \frac{\text{Pr}(D = 1 | X = 0, \text{ alcohol } < 40 \text{ g/d}, S = 1)} {\text{Pr}(D = 0 | X = 0, \text{ alcohol } < 40 \text{ g/d}, S = 1)} \]
40.5.1.7 Mantel-Haenszel法计算的95%置信区间和逻辑回归模型给出的95%置信区间估计相比有什么不同?
二者不完全一样。使用Mantel-Haenszel法计算的置信区间范围更宽。
40.5.1.8 接下来尝试使用Mantel-Haenszel法和逻辑回归模型各自进一步调整年龄。请观察年龄对吸烟和患有食道癌之间的关系有何影响。比较两种方法获得的置信区间估计。
- Mantel-Haenszel法
(976 missing values generated)
(264 real changes made)
(712 real changes made)
Maximum likelihood estimate of the odds ratio
Comparing tobacco_2==1 vs. tobacco_2==0
by alcohol_grp age_group
note: only 17 of the 24 strata formed in this analysis contribute
information about the effect of the explanatory variable
-------------------------------------------------------------------------------
alcoho~p age_gr~p | Odds Ratio chi2(1) P>chi2 [95% Conf. Interval]
--------------------+----------------------------------------------------------
0-39 gra 1 | . . . . .
0-39 gra 2 | . 0.74 0.3897 . .
0-39 gra 3 | . 0.53 0.4669 . .
0-39 gra 4 | . 5.97 0.0145 . .
0-39 gra 5 | . 3.44 0.0637 . .
0-39 gra 6 | . 3.11 0.0779 . .
40-79 gr 1 | . . . . .
40-79 gr 2 | . 1.52 0.2172 . .
40-79 gr 3 | 8.595238 5.47 0.0194 0.98028 75.36422
40-79 gr 4 | . 7.06 0.0079 . .
40-79 gr 5 | 2.500000 1.10 0.2946 0.42406 14.73848
40-79 gr 6 | . 1.10 0.2943 . .
80-119 g 1 | . . . . .
80-119 g 2 | . . . . .
80-119 g 3 | 4.631579 2.07 0.1504 0.46444 46.18758
80-119 g 4 | 0.368421 0.73 0.3943 0.03362 4.03739
80-119 g 5 | 1.714286 0.17 0.6778 0.13070 22.48431
80-119 g 6 | . . . . .
120+ gra 1 | . 0.25 0.6171 . .
120+ gra 2 | . 0.67 0.4142 . .
120+ gra 3 | . . . . .
120+ gra 4 | . 7.34 0.0068 . .
120+ gra 5 | 0.000000 0.33 0.5637 . .
120+ gra 6 | . . . . .
-------------------------------------------------------------------------------
Mantel-Haenszel estimate controlling for alcohol_grp and age_group
----------------------------------------------------------------
Odds Ratio chi2(1) P>chi2 [95% Conf. Interval]
----------------------------------------------------------------
6.973912 31.04 0.0000 3.146924 15.454919
----------------------------------------------------------------
Test of homogeneity of ORs (approx): chi2(16) = 21.16
Pr>chi2 = 0.1725- 逻辑回归模型
M4 <- glm(case ~ Tobacco_2 + as.factor(alcohol_grp) +
as.factor(age_group),
data = Oesophageal,
family = binomial(link = logit))
summary(M4); jtools::summ(M4, digits = 6, confint = TRUE, exp = TRUE)
Call:
glm(formula = case ~ Tobacco_2 + as.factor(alcohol_grp) + as.factor(age_group),
family = binomial(link = logit), data = Oesophageal)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -7.6714 1.1073 -6.928 4.27e-12 ***
Tobacco_2SMker 1.9663 0.3741 5.256 1.47e-07 ***
as.factor(alcohol_grp)1 1.3498 0.2498 5.403 6.56e-08 ***
as.factor(alcohol_grp)2 1.8679 0.2840 6.577 4.81e-11 ***
as.factor(alcohol_grp)3 3.5125 0.3831 9.168 < 2e-16 ***
as.factor(age_group)2 1.5806 1.0876 1.453 0.146132
as.factor(age_group)3 3.3632 1.0468 3.213 0.001314 **
as.factor(age_group)4 3.8336 1.0419 3.680 0.000234 ***
as.factor(age_group)5 4.1962 1.0488 4.001 6.31e-05 ***
as.factor(age_group)6 4.3755 1.1052 3.959 7.52e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 989.95 on 975 degrees of freedom
Residual deviance: 686.55 on 966 degrees of freedom
AIC: 706.55
Number of Fisher Scoring iterations: 7| Observations | 976 |
| Dependent variable | case |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(9) | 303.392825 |
| Pseudo-R² (Cragg-Uhler) | 0.419209 |
| Pseudo-R² (McFadden) | 0.306474 |
| AIC | 706.554486 |
| BIC | 755.389112 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 0.000466 | 0.000053 | 0.004082 | -6.928093 | 0.000000 |
| Tobacco_2SMker | 7.144524 | 3.431918 | 14.873381 | 5.256174 | 0.000000 |
| as.factor(alcohol_grp)1 | 3.856561 | 2.363465 | 6.292907 | 5.402894 | 0.000000 |
| as.factor(alcohol_grp)2 | 6.474554 | 3.710671 | 11.297108 | 6.576602 | 0.000000 |
| as.factor(alcohol_grp)3 | 33.533519 | 15.825306 | 71.056883 | 9.167852 | 0.000000 |
| as.factor(age_group)2 | 4.857925 | 0.576369 | 40.944982 | 1.453329 | 0.146132 |
| as.factor(age_group)3 | 28.881558 | 3.712057 | 224.712149 | 3.212957 | 0.001314 |
| as.factor(age_group)4 | 46.229816 | 5.998900 | 356.264618 | 3.679524 | 0.000234 |
| as.factor(age_group)5 | 66.431757 | 8.504718 | 518.909462 | 4.001039 | 0.000063 |
| as.factor(age_group)6 | 79.479504 | 9.110343 | 693.386792 | 3.959127 | 0.000075 |
| Standard errors: MLE |
从模型计算的结果来看,两种方法其实点估计和置信区间的估计值都很接近。不会有相互矛盾的结果。另外,Mantel-Haenszel法的计算在即使有些表格没有人数的情况下也能稳健地给出计算结果。事实上我们可以认为当存在数据分布过于稀少 (sparse data issue) 的时候,Mantel-Haenszel法可能会更加可靠。
计算结果也表明,调整了年龄和饮酒量之后,吸烟者和食道癌的比值比又略降至7.14。年龄对酒精摄入和食道癌的比值比影响似乎较小,年龄本身与食道癌呈极强的正相关。
40.5.1.9 其实饮酒量和年龄本身是可以作为连续型预测变量放入模型里。重新加载含有连续变量的数据 oesophageal_data-2.dta后,把分类变量至换成连续型变量重新拟合前一个问题的模型.尝试理解两种策略的不同及相同之处。
Oesophageal2 <- read_dta("../Datas/oesophageal_data-2.dta")
Oesophageal2 <- Oesophageal2 %>%
mutate(Tobacco_2 = as.factor(tobacco_group)) %>%
mutate(Tobacco_2 = fct_collapse(Tobacco_2,
NonSMker = "0",
SMker = c("1", "2", "3", "4")))
M5 <- glm(case ~ Tobacco_2 + age + alcohol,
data = Oesophageal2,
family = binomial(link = logit))
summary(M5); jtools::summ(M5, digits = 6, confint = TRUE, exp = TRUE)
Call:
glm(formula = case ~ Tobacco_2 + age + alcohol, family = binomial(link = logit),
data = Oesophageal2)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -8.230225 0.651144 -12.640 < 2e-16 ***
Tobacco_2SMker 1.927582 0.366357 5.261 1.43e-07 ***
age 0.064660 0.008172 7.912 2.53e-15 ***
alcohol 0.025983 0.002542 10.220 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 989.95 on 975 degrees of freedom
Residual deviance: 702.99 on 972 degrees of freedom
AIC: 710.99
Number of Fisher Scoring iterations: 6| Observations | 976 |
| Dependent variable | case |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(3) | 286.953775 |
| Pseudo-R² (Cragg-Uhler) | 0.399678 |
| Pseudo-R² (McFadden) | 0.289868 |
| AIC | 710.993536 |
| BIC | 730.527386 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 0.000266 | 0.000074 | 0.000955 | -12.639638 | 0.000000 |
| Tobacco_2SMker | 6.872871 | 3.351927 | 14.092297 | 5.261485 | 0.000000 |
| age | 1.066796 | 1.049845 | 1.084021 | 7.912217 | 0.000000 |
| alcohol | 1.026324 | 1.021222 | 1.031451 | 10.220096 | 0.000000 |
| Standard errors: MLE |
相同之处是,这两种分析手法都在说明一件事,吸烟本身和患食道癌是高度相关的,这个关系在调整了年龄,和饮酒量之后依然存在。不同之处在与比值比在年龄和饮酒量使用连续变量时似乎又缩水了一些。值得注意的是,在回归模型中决定使用连续型变量的时候,需要特别小心如何处理这些连续型预测变量。上面的模型其实还增加了另一个默认的前提条件,就是年龄,饮酒量在这个模型中默认和患有食道癌的比值的对数 (log-odds of being a case) 呈线性关系。但是,现实情况下这样的默认前提可能不能得到满足。也就是说在现实中,预测变量和结果变量的对数比值的关系很可能不是线性的。事实上你看 M4 的分析结果,饮酒量最多的那组的比值比飙得非常高。饮酒量的变量很可能就不适合用简单地连续型变量模式放入模型中。但是使用连续型变量的另一个潜在的优点是模型中需要估计的参数个数相对较少。后面的章节会仔细讨论连续型变量的处理。
40.5.2 Part 2
40.5.2.2 运用简单的表格分析三个二进制变量之间可能存在的关系。
Log_prac <- read_dta("../Datas/logistic_data_part2.dta")
tab <- stat.table(index=list(y = y,
x = x),
contents=list(count(),
percent(x)),
data=Log_prac, margins=TRUE)
print(tab, digits = 2) --------------------------------
------------x------------
y 0 1 Total
--------------------------------
0 1400.00 600.00 2000.00
70.00 30.00 100.00
1 600.00 1400.00 2000.00
30.00 70.00 100.00
Total 2000.00 2000.00 4000.00
50.00 50.00 100.00
-------------------------------- tab <- stat.table(index=list(y = y,
w = w),
contents=list(count(),
percent(w)),
data=Log_prac, margins=TRUE)
print(tab, digits = 2) --------------------------------
------------w------------
y 0 1 Total
--------------------------------
0 600.00 1400.00 2000.00
30.00 70.00 100.00
1 1400.00 600.00 2000.00
70.00 30.00 100.00
Total 2000.00 2000.00 4000.00
50.00 50.00 100.00
-------------------------------- tab <- stat.table(index=list(x = x,
w = w),
contents=list(count(),
percent(w)),
data=Log_prac, margins=TRUE)
print(tab, digits = 2) --------------------------------
------------w------------
x 0 1 Total
--------------------------------
0 1000.00 1000.00 2000.00
50.00 50.00 100.00
1 1000.00 1000.00 2000.00
50.00 50.00 100.00
Total 2000.00 2000.00 4000.00
50.00 50.00 100.00
-------------------------------- y 和 x, w 两者都有较强的相关性,但是 x, w 之间好像相互独立没有关系。
40.5.2.3 计算下列比值比:
y的x条件边际比值比 (marginal odds ratio forygivenx)。
M6 <- glm(y ~ x,
data = Log_prac,
family = binomial(link = logit))
jtools::summ(M6, digits = 6, confint = TRUE, exp = TRUE)| Observations | 4000 |
| Dependent variable | y |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(1) | 658.263028 |
| Pseudo-R² (Cragg-Uhler) | 0.202317 |
| Pseudo-R² (McFadden) | 0.118709 |
| AIC | 4890.914416 |
| BIC | 4903.502516 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 0.428571 | 0.389483 | 0.471582 | -17.364447 | 0.000000 |
| x | 5.444444 | 4.755707 | 6.232927 | 24.557037 | 0.000000 |
| Standard errors: MLE |
- 把数据分成两个部分,一部分是
w = 0,令一部分w = 1。分别计算各个部分数据里y的x条件边际比值比。
M7 <- glm(y ~ x,
data = Log_prac[Log_prac$w == 0,],
family = binomial(link = logit))
jtools::summ(M7, digits = 6, confint = TRUE, exp = TRUE)| Observations | 2000 |
| Dependent variable | y |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(1) | 406.996900 |
| Pseudo-R² (Cragg-Uhler) | 0.261072 |
| Pseudo-R² (McFadden) | 0.166566 |
| AIC | 2040.460308 |
| BIC | 2051.662113 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 1.000000 | 0.883416 | 1.131969 | -0.000000 | 1.000000 |
| x | 9.000000 | 7.073152 | 11.451755 | 17.875268 | 0.000000 |
| Standard errors: MLE |
M8 <- glm(y ~ x,
data = Log_prac[Log_prac$w == 1,],
family = binomial(link = logit))
jtools::summ(M8, digits = 6, confint = TRUE, exp = TRUE)| Observations | 2000 |
| Dependent variable | y |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(1) | 406.996900 |
| Pseudo-R² (Cragg-Uhler) | 0.261072 |
| Pseudo-R² (McFadden) | 0.166566 |
| AIC | 2040.460308 |
| BIC | 2051.662113 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 0.111111 | 0.090373 | 0.136608 | -20.846420 | 0.000000 |
| x | 9.000000 | 7.073152 | 11.451755 | 17.875268 | 0.000000 |
| Standard errors: MLE |
数据在 w 变量分组中都得到了 OR = 9,的结果,说明 w 并非 x 与 y 之间关系的交互作用变量。
y的x和w的条件比值比
M9 <- glm(y ~ x + w,
data = Log_prac,
family = binomial(link = logit))
jtools::summ(M9, digits = 6, confint = TRUE, exp = TRUE)| Observations | 4000 |
| Dependent variable | y |
| Type | Generalized linear model |
| Family | binomial |
| Link | logit |
| χ²(2) | 1472.256829 |
| Pseudo-R² (Cragg-Uhler) | 0.410570 |
| Pseudo-R² (McFadden) | 0.265502 |
| AIC | 4078.920616 |
| BIC | 4097.802765 |
| exp(Est.) | 2.5% | 97.5% | z val. | p | |
|---|---|---|---|---|---|
| (Intercept) | 1.000000 | 0.890953 | 1.122394 | -0.000000 | 1.000000 |
| x | 9.000000 | 7.590288 | 10.671532 | 25.279446 | 0.000000 |
| w | 0.111111 | 0.093707 | 0.131747 | -25.279446 | 0.000000 |
| Standard errors: MLE |
M9 的结果和预期的相同,调整了 w 之后,模型估计的 x 的比值比 OR = 9。和他们在 w 变量的各个分组数据的结果相同。
可以清楚的看到,没调整 w 时,x 的比值比 OR = 5.44。但是 w 既不是 x, y 之间关系的混杂因子,也没有有意义的交互作用。但是想要正确估计 x, y 之间的关系的话,不调整 w 计算获得的比值比是错误的,这就是体现比值比不可压缩性质的极好的例子。