第 6 章 经典测量理论 (CTT)
经典测量理论(Classical Test Theory,简称CTT),也称“真分数理论”,其基本公式为: \[X = T+E\] 其中\(X\)是观察分数, \(T\) 是真分数, \(E\)是随机分数(误差) CTT的假设:\(E(X) = T, E(E) = 0,\rho_{E T}=0\),即: 1. 在无数次测试后,考试得分会接近或等于真分数,即 \(E(X) = T\) 2. 各平行测验的误差分数的相关为0,即 \(\rho_{E_1E_2}=0\) 3. 误差 E 与真分数 T 间的相关为 0,即 \(\rho_{E T}=0\) 根据上述基本假设,可得到 \[S_{X}^{2}=S_{T}^{2}+S_{E}^{2}\]
6.1 信度的定义
根据CTT假设提出的信度概念。 - 信度:表示测量结果的稳定性程度、一致性程度,也叫测量的可靠性。
- 定义: 1.真分数方差与观测分数方差之比,即\(r_{x x}=S_{T}^{2} / S_{X}^{2}\) 2.真分数与观测分数相关系数的平方\(r_{X X}=\rho_{T X}^{2}\)
但由于误差\(E\)的存在,真分数\(T\)无法获得,所以\(S_{T}^{2}, \rho_{T}\)都无法计算,上述信度无法求解。 - 一个可操作的定义:信度表示两个平行测验间的相关系数。 \[r_{X X}=\rho_{X X^{\prime}}\]
6.2 平行测验
为了解决信度计算问题,CTT提出了平行测验(Parallel Test)的概念。 - 平行测验指能够对同一被试的同一特质作相同准确测量的不同测验形式(测验题目)。 - 严格的平行测验满足CTT的模型和假设,并且具有相同的真分数和误差标准差。 - 平行测验是一个构想的概念,要在实际的测验的编制中实现是非常困难甚至是不可能的,最多也只能说是比较接近。
6.3 测量信度
在平行测验假设的基础上,衍生出了信度估计的一些方法。
6.3.1 重测信度
- 含义:同一测验,对同一组被试前后两次施测,两次测验分数的相关系数为重测信度
- 计算方法:\(r_{X X}=\frac{\sum(X-\bar{X})(Y-\bar{Y})}{N S_{x} S_{y}}\)
- 误差来源:间隔时间
6.3.3 分半信度
- 含义:正常施测,然后将全部项目分为相等两半(奇偶分半,题目难度分半或题目内容分半等),根据各人在这两半测验的分数计算相关系数即为分半信度。
- 计算方法:
看作两个平行测验计算皮尔逊相关系数\(r_{h h}\),再进行矫正:
- 斯皮尔曼-布朗公式(方差齐性): \(r_{x x}=\frac{2 r_{h h}}{1+r_{h h}}\)
- 弗朗那根公式:\(r_{X X}=2\left(1-\frac{S_{a}^{2}+S_{b}^{2}}{S_{X}^{2}}\right)\)
- 卢仑公式: \(r_{X X}=1-\frac{S_{d}^{2}}{S_{X}^{2}}\),\(S_{d}^2=Var(X_a-X_b)\)
- 误差来源:题目内容
6.3.4 同质性信度
- 含义:测验内部所有题目间的一致性
- 计算方法:
- KR-20公式 (客观题): \[r_{X X}=\frac{K}{K-1}\left(1-\frac{\sum p_{i} q_{i}}{s_{X}^{2}}\right)\] \(K\)表示题目数量, \(p_{i}\)表示第\(i\)题的通过率, \(q_{i} = 1-p_{i}\)
- KR-21公式(客观题,且题目难易接近) \[r_{x x}=\frac{K}{K-1}\left(1-\frac{K \bar{p} \bar{q}}{S_{x}^{2}}\right)\] \(\bar{p}\)表示所有题目平均通过率, \(\bar{q}=1-\bar{p}\)
- 克龙巴赫\(\alpha\)系数 (常用 主、客观题,主客官题混合) \[r_{X X}=\frac{K}{K-1}\left(1-\frac{\sum S_{i}^{2}}{S_{X}^{2}}\right)\] \(S_i^2\)表示所有被测者第\(i\)题得分的方差
- 方差分析、因素分析
6.3.5 评分者信度
- 含义:随机抽取部分试卷,由两个或多个评分者打分,计算相关性
- 计算方法:
- 两人评分采用积差相关或等级相关,大于两人用肯德尔系数\(W\) (参考 3.3)。
- 被评对象多余7各,在\(W\)基础上可以用卡方检验 \[\begin{array}{l} \chi^{2}=K(N-1) W \\ d f=N-1 \end{array}\]
6.3.6 分层\(\alpha\)系数
一套试卷中若既含有主观题,又含有客观题,即包含多种计分方式或涉及多种测试维度的试卷的测评信度,其估计方法为分层\(\alpha\)系数(\(\alpha_{\text {strat }}\))。 - 计算公式: \[\alpha_{\text {strat }}=1-\frac{\sum \sigma_{x_{i}}^{2}\left(1-\rho_{x_{i} x_{i}^{\prime}}\right)}{\sigma_{x}^{2}}\] 其中\(\rho_{x_{i} x_{i}}\)代表测验\(X\)中某个层级\(i\)(同一计分方式、题型或维度)所有题目的测量信度;\(\sigma_{x_{i}}^{2}\)是层级\(i\)所有题目原始分的方差;\(\sigma_{x}^{2}\)是整个试卷\(X\)所有题目原始分的方差。
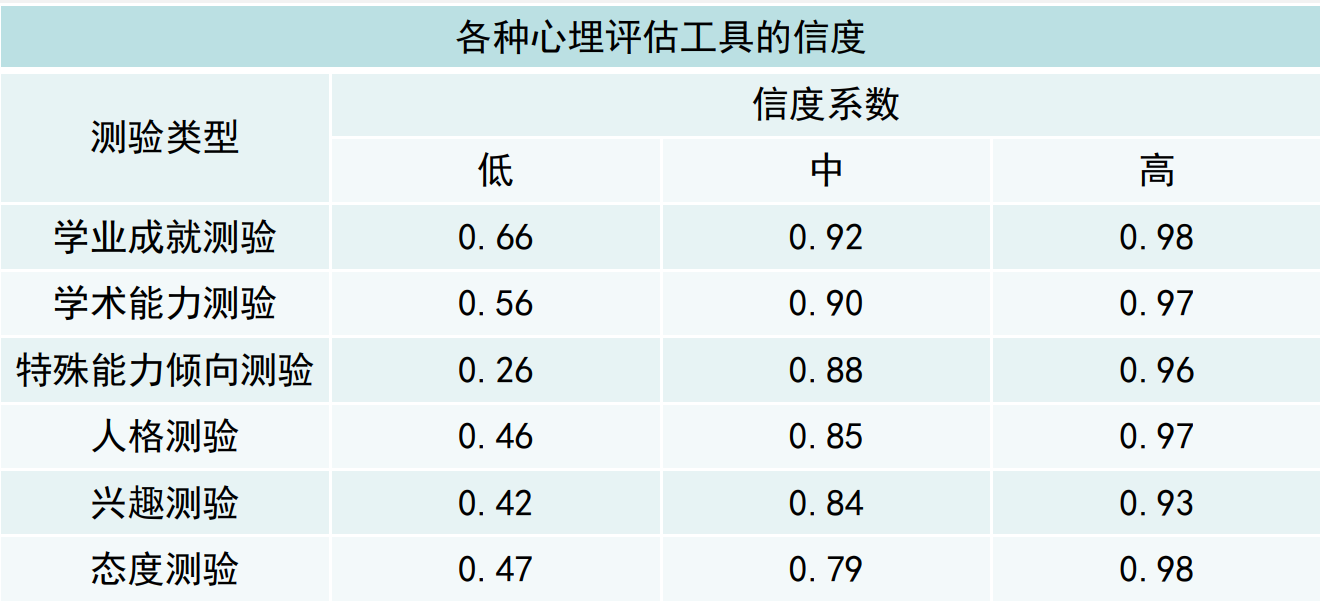
6.4 信度的作用
- 反映测量过程中随机误差大小
- 用来解释个人测验分数的意义
- 测量的的标准误:\(SE=S \times \sqrt{1-r_{X X}}\)
- 区间估计:\({X-Z\times SE} \leq T \leq {X+Z\times SE}\)
- 进行不同测验的分数比较 差异的标准误: \(SE_{d}=S \times \sqrt{2-r_{X X}-r_{y y}}\) 其中\(S\)为相同尺度的标准分数的标准差
6.5 测验的项目分析
6.5.1 测验项目的难度
二分法记分项目的难度
- 通过率 不考虑作答是否源于猜测的概率,二分法记分的测验项目常用通过率表示,即:\(P=\frac{R}{N}\),其中\(P, R, N\)分别代表项目难度,答对或通过的人数,全体被试数。
- 极端分组法 被试人数较多,可将被试者按照总分分组,总分最高的27%为被试高分组(\(N_{H}\)),总分最低的27%为被试低分组(\(N_{L}\)),分别计算高分和低分组的通过率,然后求项目难度,通过率\(P=\frac{P_{H}+P_{L}}{2}\)。\(P_{H}, P_{L}\)分别代表高、低分组的通过率。
非二分法记分项目的难度
\(P=\frac{\bar{x}}{x_{\max }}\), \(\bar{x}\)代表某项目的平均分, ,\(x_{\max }\)代表该项目满分。
难度的等距变换 通过率仅是题目的相对难度,无法进一步计算比较,需转换成等距量表。(例:4.2)
\(Z\)分数有小数点和负值,为了表示方便,常用美国教育测验服务中心采用的难度指标:\(\Delta=13+4 \cdot Z\)。 根据统计\(3 \sigma\)原则,标准正态分布的\(Z\)一般在-3到+3之间,所以等距难度指数\(\Delta\)上限为25,下限为1,平均数为13,标准差为4,\(\Delta\)越高,难度越大。
6.5.2 测验项目的区分度
- 鉴别指数: \(D=P_{H}-P_{L}\) 从分数分布两端各选择27%(27%为标准测试采用的常用惯例,一般情况下介于25%-33%之间,测试人数少于100人则不宜采用27%规则,而用50%作为分界点。)分为高、低分组分别计算通过率,两数之差就是鉴别指数。
| 鉴别指数D | 题目评价 |
|---|---|
| >0.4 | 很好 |
| 0.3~0.39 | 良好,修改后更好 |
| 0.20~0.29 | 尚可,任需修改 |
| <0.20 | 差,需淘汰 |
\(D\)缺点:该统计量无样本分布,无法进行统计处理。无法回答如“两个箱项目D值差异达到多少才具有显著差异”等问题。
- 相关法
用项目分数与总分的相关作为项目区分度指标,相关越高,项目区分度就越高。
点二列相关 适用于0、1记分(或二分变量),测验总分是连续变量的情况,计算结果需进行显著性检验,计算公式: \[r_{pb}=\frac{\bar x_p-\bar x_q}{S_t} \sqrt{pq}\] 其中,\(\bar x_p\)为通过该项目被试的平均分数,\(\bar x_q\)为未通过该项目被试的平均分数, \(p\)为通过该项目的被试人数百分比,\(q\)为未通过该项目的被试人数百分比, \(S_t\)为全体被试的分数标准差 (例:3.4)
二列相关
dnorm(qnorm(pass))适用于连续变量,但其中一个变量被认为地分成两类。例如,当一个测验项目分数是连续的,但是总分被分为高、低或及格、不及格两类时。计算公式为: \[r_{b}=\frac{\bar x_p-\bar x_q}{S_t} \cdot \frac{pq}{y}\] 其中\(y\)为正态分布下p的高度(R语言dnorm(qnorm(p))),其余同上。 二列相关系数显著性可用下公式检验: \[Z=\frac{r_b}{\frac{1}{y} \sqrt{\frac{pq}{N}}}\] 其中\(N\)为被试总人数,其余同上。\(\varphi\)相关 适用于两个变量都是二分名义变量,也可用与连续变量,\(\varphi\)相关不要求变量呈正态分布,所求指标为 \(\varphi\)系数。(例: 3.6) \[r_{\varphi}=\frac{a d-b c}{\sqrt{(a+b)(a+c)(b+d)(c+d)}}\] \(\varphi\)相关的显著性可以进行\(\chi^{2}\)检验。 \[\chi^{2}=N \cdot r_{\varphi}^{2}\]
6.5.3 项目难度的校正
客观题由于猜测本身引起误差,所以对于某些测验项目,猜测会影响项目难度的变化,因此在作项目难度比较时有必要对猜测进行校正。
选择题测验中,猜测成功的概率\(P\)受备选答案数\(K\)的影响, 备选答案数目少 ,机遇作用越大。根据难度计算公式不能反应项目真实难度,可用下式对难度校正: \[CP=\frac{K P-1}{K-1}\] 其中,\(CP\)校正后的通过率,\(P\)为实际通过率,\(K\)为备选答案数目。 对被试者得分进行校正: \[S=R-\frac{W}{K-1}\] 其中\(S\)为校正后的得分,\(R\)为被试者答对的项目数,\(W\)为被试者答错的项目数,\(K\)为项目的选项数目。